Week 5 Assignment: OS Theory Concept Map
John
Home
CPT
304: Operating Systems Theory & Design
Nelson
Stewart
2/28/2022
Throughout this course we have looked at the different
fundamental concepts that underlie operating systems. We have taken five different concepts,
features and structure of contemporary operating systems, Threads and process
synchronization, memory management, file systems, mass storage, input / output
devices, and security and protection, and created concept maps to show the
connections they have. I will also
provide a summary of the different concepts and what I have learned throughout
this course.
Concept Map:
Section 1 – Features and Structure of Contemporary Operating
Systems
User Concept Map:

-
Graphics Card: The graphics card is a
component within the computer functions similar to a CPU but focuses primarily
on completing tasks related to the graphical devices the computer uses.
-
RAM: Random access memory is the storage
location that computers usually move programs to before they are enacted upon
by the processor. These are typically the programs that the user or computer is
trying to operate on at the moment. Once a computer is powered down the
information that is stored in RAM is lost.
-
Hard Drive: The hard drive is long term
storage for information on a computer.
Unlike RAM and other memory types the hard drive is capable of retaining
information once it has stopped receiving power. A common type of hard drive is a magnetic
disk which physically writes information to a magnetic drive.
-
Input/Output Device: Input and output devices are anything that
interacts with a user or other components within the computer to move
information. Common forms of input
devices would be a mouse or keyboard and a common output device is a computer
monitor.
CPU Concept Map:

-
Multi Program: The operating system keeps
multiple jobs in memory so that the computer always has a job to work on. So if one program needs to wait for a cycle
to complete another job is loaded by the operating system to be completed while
waiting on the cycle for the first job to complete (Silberschatz, A., Galvin,
P.B., & Gagne, G. (2014). Ch 1.4)
-
Time Sharing: In multi program computers the operating
system switches between programs often enough to allow for users to interact
with the computer (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014). Ch
1.4)
-
Job Scheduling: Job scheduling is where
the operating selects between the different jobs it has in its job pool and
stores them in memory so that it can be worked on by the computer.
-
Dual Mode operation: The operating system
is able to change between kernel mode and user mode depending on the job that
needs to be completed. Kernel mode
allows the computer to complete tasks needed to proper function of the
computer. While user mode focuses on
tasks assigned by a user (Silberschatz, A., Galvin, P.B., & Gagne, G.
(2014). Ch 1.5.1)
-
Timer: The operating system enacts a
timer to determine how long a program has been running so that it can prevent
programs from getting stuck in infinite loops (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014). Ch 1.5.2)
-
Process Management: programs and tasks
that a computer is running require resources from the computer to complete. The operating system provides process
management by giving resources to hardware and other components that complete
the tasks required by the program. In
this way the operating system also prevents the computer from running out of
resources and potentially crashing (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014). Ch 1.5.2)
-
Memory Management: Computers generally
can only pull from what is called main memory. This is the memory space easiest
for the computer to access. The operating system is responsible for moving
programs into the main memory space in preparation of them being worked by the
computer (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014). Ch 1.7)
-
Storage Management: Information that is stored on a computer
needs to be organized so that it is easier for the end user to see and interact
with. The operating systems takes the
information that has been sent to the computer and organizes it in a way that
makes it easy to read and find what users and other programs are looking for
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014). Ch 1.8.1)
-
Input and Output Device Interaction: When a user goes to interact with a computer
it is very complicated to know what commands need to be entered into the
computer in order for the hardware to output the results the user is looking
for. For this the operating system
manages the commands that it receives from the user input devices and is able
to interpret them into machine code for the hardware to execute and display to
the user through an output device such as a monitor.
-
Protection: The operating system provides protection by
providing a mechanism that protects access to information or subsystems within
a computer (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014). Ch 1.9). Generally in most computers this takes the
form of requiring usernames and passwords and preventing unauthorized access to
core computer systems.
Section 2 –
How operating systems enable processes and share and exchange information
Concept Map:

Process – A process is a program in execution
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). Only once the program is actively being used
does it turn into a process. A process
also includes the text from a program, any work that is being done for the
program and any information stored in a separate location from the program that
relates to the running of the program (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
Process Sate – Process state is the different types
of activities that are being completed on a process that is running
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). The different process states are new,
running, waiting, ready and terminated.
Process Block – A process block is simply a grouping
of the information that is utilized within a process. This includes items such
as the process state, program counter, registers, memory limits and list of
open files (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Program counter: The counter indicates
the address of the next instruction to be executed for this process
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Registers: Registers vary in number and type, depending
on the computer architecture. The
include accumulators, index registers, stack pointers, and general-purpose
registers, plus any condition-code information (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014)).
-
Memory Limits: May contain items such as
value of the base and limit registers and the page tables, or the segment
tables, depending on the memory system used by the operating system
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
List of open files: The process block keeps a list of files the
process has open and is interacting with (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
Single-thread processing: is when processors
are only able to complete a process on one thread at a time. The benefit of a single-thread process is it
is much easier to program and there is less chance of errors or complications
coming in the process. This makes a
single-thread more reliable than a multi-thread process. The downside is that singe thread processing
is much slower than multi-thread
processing. There is also the
chance that the thread in the process will get locked up with an error or have
a long task to complete and block any other tasks from completing
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
Multi-thread processing: is when processors are able to complete a process with multiple threads at a time. This gives the advantage of being able to complete different parts of the process in parallel which improves the speed and performance of a computer. This also allows process to complete if one thread gets locked up or has to handle a particularly long task. The downside to multi-thread processing is that it requires complex programming and requires an experienced programmer to take full advantage of the technology. There is also the chance that two threads trying to complete the same task will require the same resources. If the resources are not available both tasks can get stuck and not be able to complete until more resources become available or until the error is handled.
Multi-Thread Models:
-
Many-to-One Model: the many to one model maps many user level
threads to single kernel thread. Thread
management is done by the thread library in user space, so it is efficient. But if the thread make a blocking system call
the entire process will be blocked (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
-
One-to-One Model: The one-to-one model
maps each user thread to a kernel thread. This is beneficial because it allows
for multiple threads to run in parallel with each other and does not stop the
entire process if there is a blocking call.
The downside to this model is creating so many kernel threads can be
resource intensive (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Many-to-Many Model: The many-to-many
model multiplexes many user-level threads to a smaller or equal number of
kernel threads. The number of kernel
threads may be specific to either a particular application or a particular
machine. The biggest benefit of the
many-to-many model is that it does not suffer from the problem of potential
blocks stopping the program and it only schedules as many kernel threads as it
needs so the resource problem is resolved (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014)).
Critical-Selection Problem: The critical
selection problem is where two processes are trying to interact with a critical
section at the same time. A critical
variable would be something like changing a common variable, updating a table,
writing a file, etc.. (Silberschatz, A., Galvin, P.B., & Gagne, G.
(2014)). Their is need for something
that ensures mutual exclusion where only one process can interact with a critical section at a time, progress where
programs not executing in remainder sections can decide which process will enter
into its critical section, and bounded waiting which creates a limit to how
many times other processes can enter there critical sections after a process
has made a request for a critical section before the access is granted
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). Without a solution to handle the three
problems tasks would be trying to interact with critical files at the same time
and potentially interfering with a critical function which could cause damage
to the files or prevent data from getting to where it needs to go and causing
the process to not function correctly.
Section 3 – Memory Management
Concept Map:

Protection of memory space: each process has to have a separate memory
space to ensure that the processes are protected from each other and is
fundamental to having multiple processes loaded into memory for concurrent
execution (Silberschatz, A., Galvin,
P.B., & Gagne, G. (2014)).
o
Limit Register: specifies the size of the
range (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). Contains the range of logical
addresses(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Relocation Register: contains the value
of the smallest physical address (Silberschatz, A., Galvin, P.B., & Gagne,
G. (2014)).
o Memory: When a process arrives and needs memory, the system searches the set for a hole that is large enough for this process. The hole may be too large and is split into two parts. One part is used for the arriving process and the other hole is returned to the set of holes for future use (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
Logical memory Space
-
The logical address space is a collection of
segments (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). When programmers work with memory they prefer
to think of it as a set of fragments. It does not matter what the order of
fragments are. Each segment is
identified by its elements and that is how the programmer identifies the memory
they are targeting (Silberschatz, A., Galvin, P.B., & Gagne, G.
(2014)).
Section 4 – Mass Storage and Input/Output devices

Objectives and Functions
-
Provides medium to write data to secondary
storage systems (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Provide system calls to read, write, create,
reposition, delete and truncate files (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
o
Create: space in file system must be
found for the file and an entry for the new file must be made in the directory
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Writing: make a system call specifying
both the name of the file and the information to written to the file. (Silberschatz,
A., Galvin, P.B., & Gagne, G. (2014)).
o
Read: use a system call that specifies
the name of the file and where (in memory) the next block of the file should be
put. (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Reposition: directory is searched for the
appropriate entry, and the current-file-position pointer is repositioned to a
given value. (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Delete: search the directory for the
named file. Once file is found release all file space so it can be re-used. (Silberschatz,
A., Galvin, P.B., & Gagne, G. (2014)).
o
Truncating: deletes contents of a file
without deleting the files attributes. (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
-
Sets rules around open files and how they are
handled through file pointers, file-open count, disk location of the file, and
access rights.
o
File pointer: On systems that do not
include a file offset as part of the read() write() system calls, the system
must track the last read-write location as a current-file-position pointer
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
File-open count: As files are closed, the operating system
must reuse its open-file table entries, or it could run out of space in the
table (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Disk location of the file: Most file
operations require the system to modify data within the file. The information
needed to locate the file on disk is kept in memory so that the system does not
have to read it from disk for each operation (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014)).
o
Access rights: each process opens a file
in an access mode. This information is
stored on the pre-process table so the operating system can allow or deny
subsequent I/O requests (Silberschatz, A., Galvin, P.B., & Gagne, G.
(2014)).
-
Reads file extensions on the saved files to
determine how the data should be read (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)). Weakness of file extensions is that they only
work if the program has been told what that extension means. In windows and apple extensions generally
allow the OS to know what kind of file is being run and what systems it needs
to use. In OS like Unix though a
different form is used and extension do not have the same meaning
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Determines how data can and should be accessed
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
Directory Structure
-
Directory operations are search for a file,
create a file, delete a file, list a directory, rename a file, traverse the
file system (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Search for a file: we need to be able to
search a directory structure to find the entry for a particular file (Silberschatz,
A., Galvin, P.B., & Gagne, G. (2014)).
o
Create a file: New files need to be
created and added to the directory (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
o
Delete a file: When a file is no longer
needed, we want to eb able to remove it from the directory (Silberschatz, A.,
Galvin, P.B., & Gagne, G. (2014)).
o
List a directory: We need to be able to
list the files in a directory and the contents of the directory entry for each
file in the list (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Rename a file; Because the name of a file
represents its contents to its users, we must be able to change the name when
the contents or use of the file changes (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
o
Traverse the file system: We may wish to
access every directory and every file within a directory structure. For reliability, it is a good idea to save
the contents and structure of the entire file system at regular intervals
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Some types of directory structures are
single-level directory, two-level directory,
o
Single-Level Directory: the simplest
directory structure is the single-level directory. All files are contained in the same
directory, which is easy to support and understand (Silberschatz, A., Galvin,
P.B., & Gagne, G. (2014)).
Limitations to this directory structure though is that all files are in
the same directory for all users and files must have unique names. As the number of files increase and the
number of users increases it become more likely for duplicates to occur or for
users to forget names of files they have created (Silberschatz, A., Galvin,
P.B., & Gagne, G. (2014)).
o
Two-Level Directory: In a two-level directory system each user
is given their own user file directory.
This makes it so that files saved by a user only show up under their
user directory and users are able to have files with the same name saved since
they are in different locations (Silberschatz, A., Galvin, P.B., & Gagne,
G. (2014)). A disadvantage to two-level
directory is that each users information is kept separate and isolated from one
another. If users want to share
information they need permission from the system to do so. If they get permission they then need to be
able to identify the file they are looking for by using a path name to identify
where the file is that they are looking for and who owns it v
o
Tree Structure Directory: a tree structure directory is structured
similar to a two-level directory with the exception that it can move beyond a
user file path. Each level of the
directory is able to branch into many other branches of files. Allowing for many different file locations to
be kept (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
o
Acyclic-Graph Directory: Acyclic-graph directory is a generalization of
a tree branch directory. Using the same
general layout in an acyclic-graph directory a file can be shared within a sub
directory of two separate users. The shared file can only be worked on and
utilized by one user at a time but once it is updated the file will appear
updated in both users directories (Silberschatz, A., Galvin, P.B., & Gagne,
G. (2014)).
Input Output Devices (I/O)
There are many different forms of I/O devices ranging from a
mouse and keyboard on a home computer, to a control stick within an airplane,
to a keypad on a bank machine. The
primary purpose of the I/O device is to allow command signals to be sent from a
user or piece of hardware to the computer in order to get a task completed
(Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)). The most visible layer of I/O devices is
the hardware layer. The hardware layer consist of the hardware that is used to
send the electronic commands to the computer.
An example of this would be a game controller. The game controller consists of many
different hardware components that work together to generate signals that can
be sent to the computer through connection ports (Silberschatz, A., Galvin,
P.B., & Gagne, G. (2014)). Some I/O
devices have their own software contained on chips and circuit boards attached
to the device. Instead of having the
computer do all the error handling and information mapping the devices perform
this task to reduce the workload on the PC (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014)).
Section 5 – Mechanisms necessary o control he access
of programs, processes or users
Concept Map:
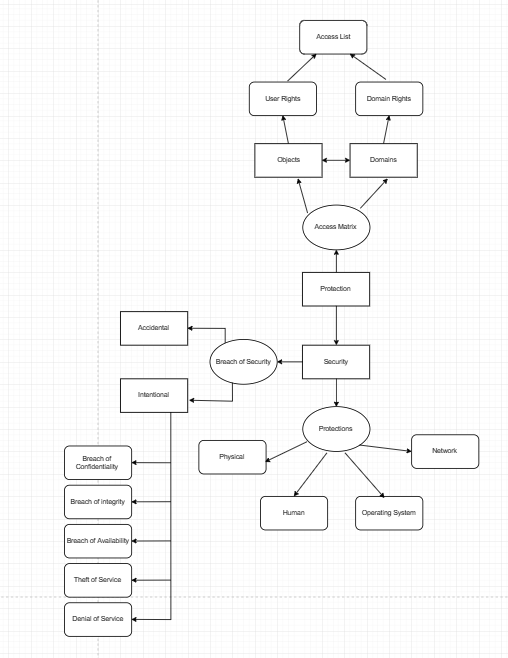
-
Breach of Confidentiality: This type of violation involves unauthorized
reading of data (or theft of information).
In
this type of breach the user is looking to gain access to information they are
not supposed to have (Silberschatz, A., Galvin, P.B., & Gagne, G. (2014)).
-
Breach of Integrity: This type of violation involves unauthorized
modification of data. This type of
attack could be something like changing the code of an important program within
a company to prevent it from functioning as intended (Silberschatz, A.,
Galvin, P.B., & Gagne, G. (2014)).
-
Breach of Availability: This violation involves unauthorized
destruction of data. This type of attack
is usually orchestrated by a bad actor who is looking to create chaos and make
a name for themselves by creating as much disruption as possible. These types of attacks are usually very
noticeable and specific to the attacker (Silberschatz, A.,
Galvin, P.B., & Gagne, G. (2014)).
-
Theft of Service: This type of violation involves
unauthorized use of resources. This type
of attack can take the form of installing software on some ones computer to
allow a hacker to use it to store files or spoof where their internet traffic
is coming from so they are harder to find (Silberschatz, A.,
Galvin, P.B., & Gagne, G. (2014)).
-
Denial of Service: This violation involves preventing
legitimate use of the system. This form
of attack can happen accidentally pretty easily. It is common for this kind of attack to come
in the form of a high number of repeated requests or delivery of packets over
the internet to prevent any other information from being able to be
processed. Most attacks we hear about in
the news on video game companies come in this form to shut down servers and
prevent people from playing the game (Silberschatz, A., Galvin, P.B.,
& Gagne, G. (2014)).
In order to prevent breaches and protect systems there are
different security measures that can be taken:
-
Physical:
Physical security involves preventing hackers or people with malicious
intent from getting physical access to a system. This can take the form of ensuring servers
and network devices are kept behind locked doors that only specific people have
access too. To locking desktops closed
so that it is more difficult for people to get to the components within.
-
Human:
Human security is particularly tricky because it is also the most
vulnerable point. A large portion of
attacks on computer systems come from social engineering attempts where hackers
will attempt to get information out of a user such as their username or password
so that they can gain access to a network and look like it is a legitimate
user. It is very important for people to
be careful with their passwords and network logins and never share them or have
them in a location that is easily accessible.
-
Operating System: The system must protect itself from
accidental or purposeful security breaches.
A process that fails to terminate can accidentally cause a denial of
service or poor programming can allow a hacker to gain information from the
operating system by granting access to memory spaces that they would not
normally have access to (Silberschatz, A., Galvin, P.B., &
Gagne, G. (2014)).
-
Network:
Especially today protecting systems from unauthorized access over a
network has become very important. Network
engineers and network specialists but ensure that the only traffic allowed into
an environment through the internet is traffic that is expected. A common form of attack on a network is piggy
backing where malicious code can get into a network by mixing with legitimate
traffic. It is also important to prevent
hackers from being able to probe into a network and gain information to help
them find more vulnerabilities.
Summary
Looking through the stuff I learned throughout this course I
found that even though the concepts are simple to understand there is a lot of
steps the operating system needs to go through in order to function
properly. There are the portions of the
CPU processes that work around keeping programs running as smooth as
possible. I was unaware of how difficult
it was for a processor to keep all the different tasks in synch and figure out
what processes need to be worked on based on the task being performed. The
operating system is tasked with keeping the information that is being input by
the computer as well as by the user. Because
of this it needs to be able to focus on many different tasks at once. One of the big things I did not take into
consideration is how the CPU is able to take multiple tasks and split it up
amongst multiple threads to get processes completed much faster. This being said I found it interesting how
this was not always the best situation depending on the different tasks that
the operating system may need to accomplish.
I really didn’t think about how some operating systems may be simple and
designed for only specific single tasks unlike windows which is designed to
handle large complex interactions.
Operating systems being able to process multiple tasks involves
them being able to determine what is the most important task and what is the
oldest task. Through this information the
operating system needs to be able to prioritize where it is going to pull
information from and decide what information is important enough to move from
standard slow memory location to high speed locations. This movement of information helps the
operating system complete tasks as fast as possible.
Within the operating system a computer can create memory
spaces that are dedicated to specific tasks.
This space can be from virtual memory where information is stored
temporarily until it is used. It can also create long term memory spaces for
long term storage to keep information from different users and different
process separate. With different users potentially accessing information
from different file locations or the same file locations directly through a
computer or a network it is important for the operating system to be able to
determine where the access request is coming from, who is making the request, and
if they are allowed to access the information.
The security of information is a big portion of what the
operating system is responsible for. Keeping
files safe from being cross contaminated by multiple processes as well as keeping
information safe from users who may intentionally or un-intentionally attempt
to break into a system. Through this the
operating system utilizes a series of features such as user access control and
process limitations to ensure that only people and process that should be
interacting with information are able to do so.
With my current career being in information technology as a
system administrator the concepts I have learned in this class have helped me
get a better understanding of the day to day interactions I have with the
different systems within my network. I had
a high level understanding of most of the concepts that we went over but some
of the finer details we learned help me understand the nuances of why certain
things are done in certain ways or how some items worked. One specific item that comes to mind is how
the task scheduling and threading within the CPU’s work together to make the
computer run or potentially cause issues.
This is something that I can look back at different situations and think
that with that information I would have been able to make better
recommendations or provide a faster solution.
References
-
Silberschatz, A., Galvin, P.B., & Gagne,
G. (2014). Operating system concept essentials (2nd ed). Retrieved
from https://redshelf.com/
Comments
Post a Comment